How does Caching Work?
Im going to try and explain Web Caching in a simple way using simple images with simple descriptions. The topic of Web Caching is more complex than this, but this explanation should give you a good idea what is going on and, in general, how it is working.
First you need to know, when you “go to” a webpage, you are actually requesting a “representation of a resource”. A resource being pretty much anything with a URL available on the Internet, and a representation is basically a copy. So all that to say you ask a website for a copy of a webpage or resource for a webpage (i.e. an image) so you can look at it in your Web Browser.
Now lets walk through an example. You are browsing the Internet looking at cat pictures. One web request might look something like:
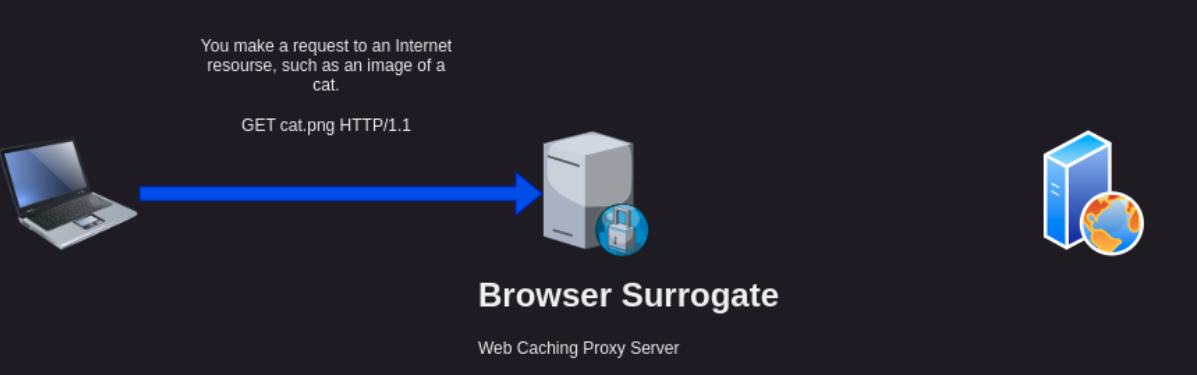
In the image we can see your laptop is making a request for the resource ‘cat.png’. Because you are using the Browser Surrogate, which is a caching proxy, your Browser is going to ask the Browser Surrogate if it has this ‘cat.png’ resource?
The Browser Surrogate will check its cache for the resource and return it if the resource is “fresh”. Fresh, meaning the Origin server will tell the Browser Surrogate how often it needs to re-fresh its copy of a resource. So, if the resource is “stale” or the Browser Surrogate doesn’t have a copy, it will forward the request to the Origin server, that is the server that has the original copy of the resource.
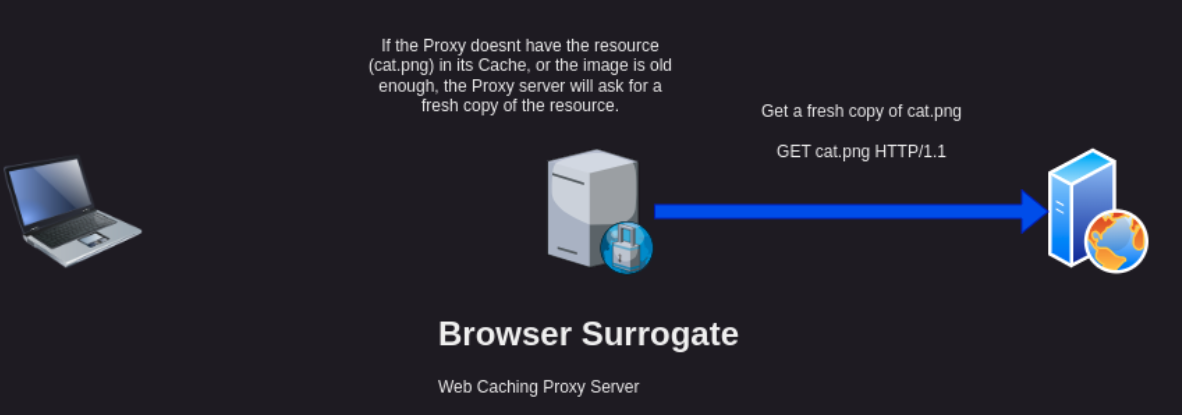
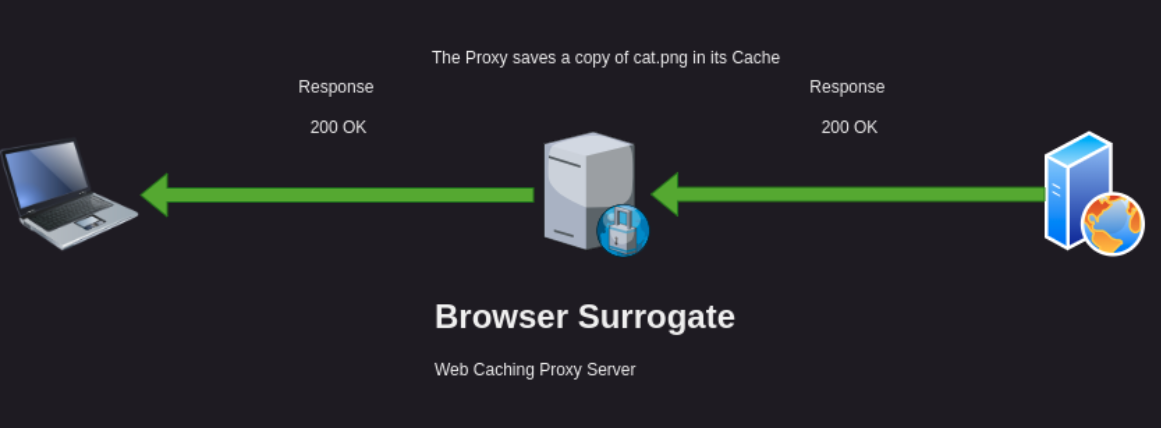
Lets assume the Browser Surrogate must request a copy from the Origin server. This is like any other web request which will result in the Browser Surrogate caching a fresh copy of the resource and returning a copy to the user.
Now lets assume some time has gone by and you visit that page with that cute cat picture again. This time the request only needs to hit the Browser Surrogate and you will get a fresh copy of the ‘cat.png’ without having to send the request all the way to the Origin server.
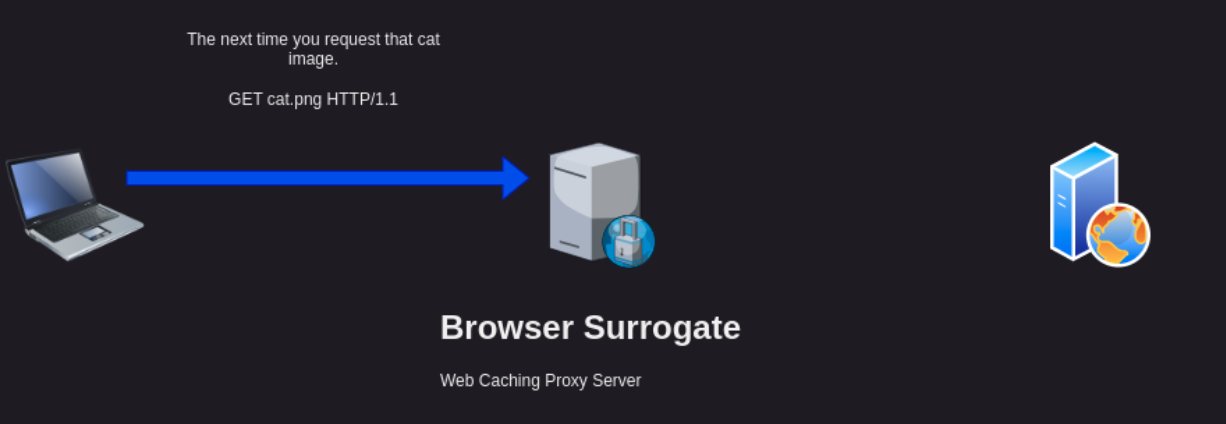

As you can imagine, since the request could be handled by the Browser Surrogate, you will get your response of ‘cat.png’ in less time. This is one of the primary reasons for Web Caching, to help webpages load more quickly by saving temporary copies of frequently accessed Internet resources.